Método de la Secante
Es una variación del método de Newton-Raphson donde en vez de calcular la derivada de la función en el punto x0 se usa la aproximación a la derivada dada por:
aproxdf= (f(x)-f(x0))/(x-x0)
La que representa la pendiente de la recta secante que une los puntos (x0,f(x0)) y (x,f(x))Este método es de especial interés cuando es difícil derivar la función de estudio, por lo que el método de Newton no resulta atractivo.
Preliminares
- El concepto de la derivada de una función en un punto x0 puede expresarse como el límite de la pendiente de la recta secante que une a los puntos (x0,f(x0)) y (x,f(x)) cuando x->x0. es decir (lim x->x0) (f(x)-f(x0))/(x-x0)
- Por lo anteriormente expuesto el cociente (f(x)-f(x0))/(x-x0) puede usarse como una aproximación de la derivada cuando x esta cercano a x0 y esta es usada por el método de la secante para sustituir a la derivada de la función
Por lo tanto el método de la secante sigue el mismo algoritmo que el método de Newton-Raphson excepto que se sustituye la derivada de la la función en el punto x0 por su aproximación. Otra diferencia es que usa 2 puntos iniciales en lugar de uno.
Una buena exposición del método la pueden ver en:
https://es.wikipedia.org/wiki/M%C3%A9todo_de_la_secante
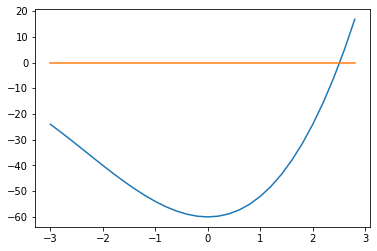
EJEMPLO: Calcular la raíz de la ecuación f(x)=x**3+7*x**2-60, usando el métodos de de la Secante.
Antes que nada realizamos la gráfica para ubicar 2 puntos cercanos a la raiz. Observando la gráfica adjunta podemos seleccionar x0=1 y x1=2 como puntos iniciales.
GRAFICA DE f(x)=x**3+7*x**2-60,
PROGRAMA EN PYTHON
def f(x): return x**3+7*x**2-60
x0=1; x1=2
tol=0.01; n=20
for i in range(n):
aproxdf=(f(x1)-f(x0))/(x1-x0)
x=x0-f(x0)/aproxdf
err= abs(x-x0)
print(i,x0,x,err)
if err<tol:
print(“\n”,”convergencia alcanzada”)
print(“numero de iteraciones”,i)
print(“Raiz= “,x)
break
x0=x1; x1=x
Método de la regla falsa
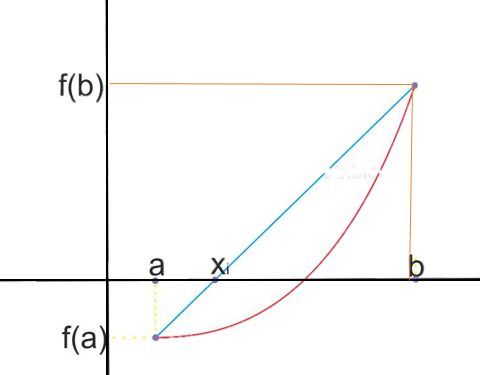
El método de regla falsa o falsa posición, es un método iterativo similar al método de la biseccion. La única diferencia con este método es la formula iterativa para actualizar la raiz, la cual es:
xm=(b*f(a)-a*f(b))/(f(a)-f(b))
Esta formula representa el punto donde la curva f(x) intercepta al eje x. Ver grafica
Para codificar el método de la Regla Falsa, usamos el mismo código que para el método de la biseccion excepto que reemplazamos la formula para xm.
PROGRAMA EN PYTHON
EJEMPLO. Resolver la ecuación: x^3+7x-60=0
Antes de empezar la codificación, se realiza un estudio preliminar( el gráfico ayuda en esto) para seleccionar 2 puntos, a y b, tal que sus imágenes tengan signos diferentes, es decir, f (a)*f (b) <0. En esta caso, observando la gráfica podemos visualizar que entre a=2 y b=3 hay un cambio de signo de f(x). Por lo tanto según el teorema de Bolzano existe una raiz de f(x) entre a=2 y b=3
E este programa resolvemos la ecuación: x^3+7x-60=0, usamos el mismo programa que el metodo de la biseccion excepto que reemplazamos la formula para xm.
CODIGO
import matplotlib.pyplot as ptl
import numpy as np
def f(x): return x**3+7*x**2-60
a=1;b=3;n=30;tol=0.01 # valores iniciales
plt.plot(x,f(x))
plt.plot(x,0*x)
xant=0
for i in range(n):
xm=(b*f(a)-a*f(b))/(b-a)
print(xm)
err=np.abs(xm-xant)
print("\n"," solucion parcial iteracion",i)
print("raiz,error",xm,err)
print("imagenes f(a),f(b),f(xm)",f(a),f(b), f(xm))
if err<tol:
print("\n","convergencia alcanzada")
print("numero de iteraciones",i)
print("Raiz= ",xm)
break
else:
if f(a)*f(xm)> 0 :
a=xm
print("cambia a, a=xm ")
if f(a)*f(xm)< 0 :
b=xm
print("cambia b b=xm")
METODO PTO. FIJO
El Método de Punto Fijo, es otro método para resolverla ecuación f(x) = 0, para ello se reordena la ecuación en una forma equivalente despejando x y la función resultante se denota por g
Ejemplo: Resolver x**3-x-1=0
Despejamos x.
Hay 2 despejes posibles(los denotamos por g1(x) y g2(x))
g1(x)=x**3-1 y g2(x)=(x+1)**(1/3).
Se toma uno de los dos despejes y se aplica reiteradamente
X1=g(x0),
x2= g(x1),
x3= g(x2)
…
Xn=g (xn-1)
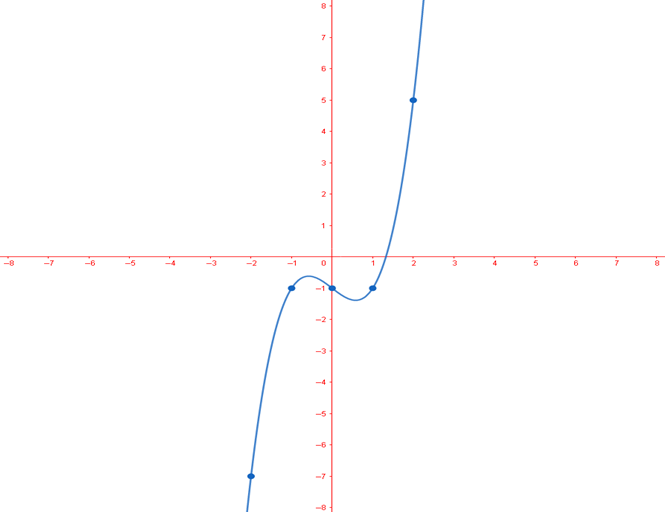
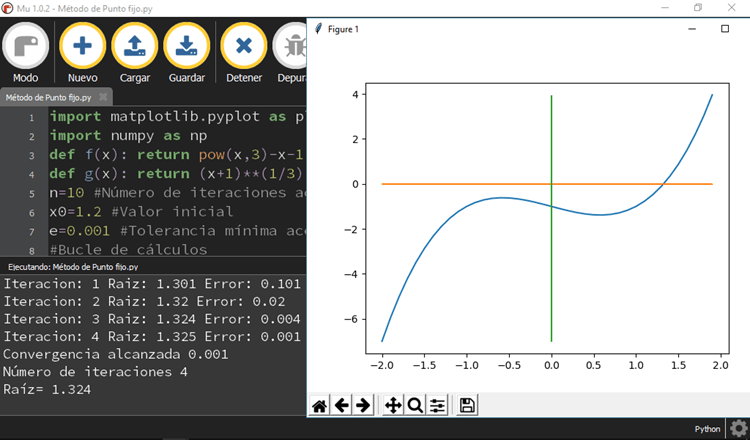
Mediante el metodo grafico se puede tomar x0=1.2 como valor inicial
Codigo en Python
import numpy as np
import matplotlib.pyplot as plt
def f(x): return x**3-x-1
def g(x): return (x+1)**(1/3)
n=10 #Número de iteraciones aceptadas
x0=1.2 #Valor inicial
e=0.001 #Tolerancia mínima aceptada
#Bucle de cálculos
for i in range(10):
x1=(x0+1)**(1/3)
error= abs(x1-x0)
print(“Iteracion:”,i+1,”Raiz:”,round(x1,3),”Error:”,round(error,3))
if (error < e):
print(“Convergencia alcanzada”,round(e,3))
print(“Número de iteraciones”,i+1)
print(“Raíz=”, round(x0,3))
break
x0=x1
x = np.arange(-2.0,2.0,0.1)
y = np.arange(-7.0,4.0,0.1)
plt.plot(x,f(x)) # Dibujo de la funciÓn
plt.plot(x,0*x) # Dibujo del eje x
plt.plot(y*0,y) # Dibujo de la funciÓn
plt.show() # Dibujo en la pantalla
corrida